
Principais Técnicas de Machine Learning
Se quiser aprender mais sobre machine learning vá além do Python.
Algoritmos x Técnicas
Embora esse artigo seja focado nas técnicas de machine learning, vamos falar brevemente sobre os algoritmos.
Não são a mesma coisa?
Genericamente falando uma técnica é uma maneira de resolver algo. Agora quando temos um algoritmo, queremos dizer que temos uma entrada e precisamos de uma saída, onde com o algoritmo damos os passos para chegar até a saída. Logo o algoritmo pode usar várias técnicas para chegar na saída.
Técnicas de machine learning
-
Regressão: na maioria dos livros de estatística, encontramos regressão como uma medida de como a média de uma variável e os valores correspondentes de outros valores de relacionam entre si.
-
Regressão média: o primo de Charles Darwin, Francis Galton observou ervilhas durante anos (esse experimento junto com o Mendel foram muito importantes para o avanço dos estudos da genética). Ele concluiu que deixar a natureza fazer o seu trabalho resultaria em diversos tamanhos de ervilhas. A natureza no comando, ervilhas maiores começam a produzir descendentes menores com o tempo. Bom, temos um certo tamanho para ervilhas que variam, mas podemos mapear esses valores para uma linha ou uma curva específica.
Mas o que a regressão tem a ver com o machine learning?
Com determinada técnica a regressão encontra sua base no aprendizado supervisionado. Isso é baseado para prever algo contínuo e numérico e começamos trabalhando nos valores do conjunto de dados que já conhecemos, comparando os valores conhecidos e previstos e identificar a diferença entre os valores esperados e previstos como erro.
Tipos de regressão que são utilizadas no machine learning:
-
Regressão linear: quando podemos observar a relação entre um alvo e um preditor em uma linha reta, por exemplo: y = P1x + P2 + e
-
Regressão não linear: Quando é observada uma relação não linear entre alvo e preditor, e não é uma linha reta.
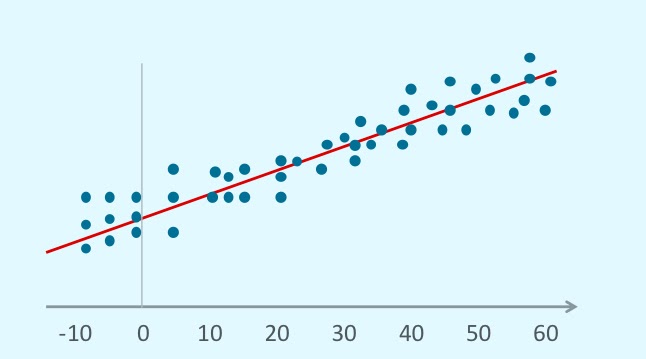 Neste gráfico, a linha se ajusta melhor a todos os dados marcados pelos pontos. Usando essa linha, podemos prever quais valores encontraremos para x = 70 (com um grau de incerteza).
Neste gráfico, a linha se ajusta melhor a todos os dados marcados pelos pontos. Usando essa linha, podemos prever quais valores encontraremos para x = 70 (com um grau de incerteza).
Classificação
A classificação é uma técnica de mineração de dados que nos ajuda a fazer uma previsão de participação em grupos para instância de dados. Isso usa dados rotulados com antecedência que é um tipo de aprendizado supervisionado. Isso quer dizer que que treinamos dados e esperamos “prever o futuro”, e essa previsão quer dizer que classificamos os dados em dois atributos:
- Atributo de saída ou atributo dependente
- Atributo de entrada ou atributo independente
Métodos de classificação
- Indução da árvore de decisão: uma árvore de decisão da classe tuplas rotuladas, isso possui ‘nós’ internos, ramificações e ‘nós’ de folha. Os nós internos possuem o teste em um atributo, as ramificações, os resultados do teste, os nós da folha e o rótulo da classe. Os envolvidos são, aprender e testar.
- Classificação baseada em regras: é baseada em um conjunto de regras (IF-THEN, ou seja, IF - condição e THEN - conclusão).
- Retropropagação: o aprendizados da rede neural é também conhecido por construir conexões. A retropropagação é um algoritmo de aprendizado bem popular, pois ele iterativamente processa dados e compara o valor alvo com os resultados a aprender.
- “Preguiçosos”: numa abordagem mais preguiçosa, a máquina guarda uma tupla de treinamento e aguarda outra tupla de teste. Isso suporta o aprendizado incremental e contrasta com a abordagem inicial do aprendiz.
Clustering
É uma classificação não supervisionada. É uma análise de dados exploratória sem dados rotulados disponíveis. Com o agrupamento, separamos os dados não rotulados em conjuntos finitos e discretos de estruturas de dados naturais. Eles também se dividem em dois tipos:
- Clustering difícil: um objeto pertence a um único cluster.
- Clustering flexível: um objeto pertence a vários clusters.
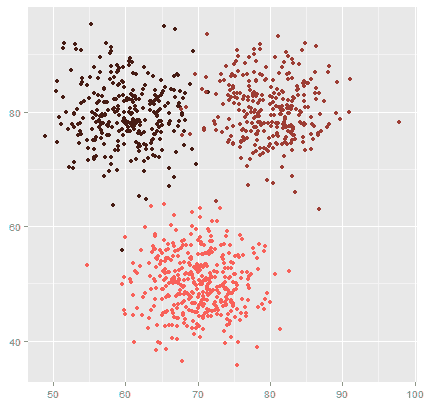
É assim que um cluster se parece: Código QR, Aztec e Data Matrix estariam em um grupo; nós poderíamos chamar isso de códigos 2D. Os códigos de barras da ITF e os códigos de barras da Code 39 seriam agrupados em uma categoria de ‘Códigos 1D’.
Detecção de anomalias
Anomalia é algo que desvia do curso esperado. Com o machine learning, também (nem sempre) podemos querer detectar uma anomalia. Um exemplo seria detectar uma conta de dentista 85 obturações por hora. Isso equivale a 42 segundos por paciente. Outra seria encontrar uma nota especial do dentista apenas às quintas-feiras. Tais situações levantam suspeitas e a detecção de anomalias é uma ótima maneira de destacar essas anomalias, já que isso não é algo que procuramos especificamente.
Bom, por enquanto isso é tudo sobre algumas técnicas de machine learning utilizando python. Não quis entrar em detalhes de códigos pois já existe bastante material pela internet que detalha mais os códigos de cada técnica, meu objetivo aqui era entrar na parte teórica de cada uma. Espero que tenham gostado.
{kind=link}